SSD FTL #
SSD FTL provides an indirection over physical address space in conformity to disk HAL. Because block update is never in-place, a mapping from logical to physical address is thereby needed.
Block-based #
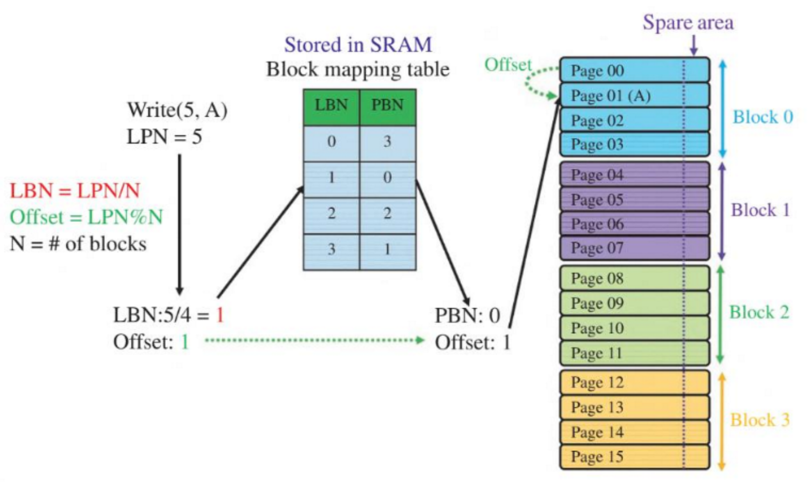
A write proceeds as followed:
- Calculate logical block number (LBN) from request LPN
- Lookup physical block number (PBN) from mapping table
- Write to the offset in the physical block
- if it’s been occupied, update it by writing to another free block at the same offset and copy valid data over.
Remark #
- Pro: mapping table space is not big
- Cons: large amount of GC due to the difficulty of finding blocks with specific free page offset
Page-based #

Remark #
- Pro: mapping table space is huge. Require 1GB with 1TB SSD
- Cons: higher associative increases the chance of finding free page in opened block
Hybrid-FTL #
Motivation: harness the space efficiency benefit of block-based FTL, use small amount of page-based to record updates. For example, if 90% of a 512-GB SSD (128 KB block) is covered by block-level mapping, the hybrid FTL only needs 117 MB instead of 1 GB for full page-based. 3
- A new page is written to data page, and subsequent updates to that page will go to a log block
- Log blocks are highly limited (in order to keep FTL size small); when log blocks run out, merge is required
- Log block can be fully-associative or block-associative (like CPU cache):
- In case of fully-associative log block (a log block can take updates from any data page and a data page scatters its updates in multiple log blocks), a full merge incurs recursively copying pages.
- In case of block-associative, log block thrashing will be problematic.

Another way of thinking about hybrid-FTL 5 #
A hybrid FTL uses page-level mappings for new data and converts them (merge) to block-level mappings when it runs out of mapping cache.

The left write-order is fully sequential (ordering + co-location), and requires only switch merge
The right write-order has co-location only, and requires full merge to reorder pages
Remark #
Just a postponed version of block-based FTL. Performance suffers when it fallbacks to block-based FTL at high update period
- Pro: mapping table space is huge. Require 1GB with 1TB SSD
- Cons: expensive full merge cost
On-Demand: DFTL 4 #
The de facto FTL today.
Motivation
- For workload with high temporal locality, it suffices to store the working set of page-based translation blocks in SRAM, while leaving the cold ones in flash.
- The architecture is reminiscent of TLB.
- In its Cached Mapping Table, instead of caching an entire translation page, it only caches entries
- Unlike the offset-based lookup in normal table, it’s a fully-associative dictionary
Architecture

- Cached Mapping Table: an LRU-based fully-associative dictionary like TLB, which relies on temporal locality to achieve good cache hit rate
- Global Translation Directory: the table that tracks translation blocks
- How to read and write?
- Current Data Block: ingest new writes
- Page-based mappings allow sequential writes within these blocks, thus conforming to the large-block sequential write specification.
- For write (and update) requests, DFTL allocates the next available free page in the Current Data Block, writes to it and then updates the map entry in the CMT
- even page-sized random scattered I/O becomes sequential thanks to out-place update
- johnson: each channel has one open block for incoming write
- although an open block can write in the specificed zig-zag sequence, the problem is that update will invalidate pages and as free blocks are depleted, the cost of live data copy is the real cost of random update
GC
- GC triggered when number of free blocks drop below threshold
- If victim block is a data block
- Copy valid pages to Current Data Block
- Lazy copying: don’t update translation page now, if the translation entry is in CMT, directly update it (will eventually be updated upon eviction)
- Batch update: the victim block’s translation entries are in the same translation page, so they can be updated together
Performance
- Few dirty write-back: approximately 97% of the evictions in read-dominant TPC-H benchmark did not incur any eviction overheads.
- The worst-case overhead includes: two translation page reads (one for the victim chosen by the replacement algorithm and the other for the original request) and one translation page write (for the victim) when a CMT miss occurs
- the presence of multiple mappings in a single translation page allows batch updates for the entries in the CMT, physically co-located with the victim entry
- Read up one page, update multiple entries and writeback
- Optimization: scan in CMT for dirty entries to reduce critical-path eviction
- the presence of multiple mappings in a single translation page allows batch updates for the entries in the CMT, physically co-located with the victim entry
Reference #
(512GB / 256KB * 0.9 + 512GB / 4KB * 0.1) * 8bytes = 117MB, assume each PTE consumes 8 bytes (check!) ↩︎http://www.cse.psu.edu/~buu1/papers/ps/dftl-asplos09.pdf ↩︎ ↩︎
The Unwritten Contract of Solid State Drives: http://pages.cs.wisc.edu/~jhe/eurosys17-he.pdf ↩︎