SSD Parallelism #
Individual NAND chip exhibit low throughput (~40 MB/s), however; when request is striped over multiple of them, the cumulative throughput can be phenomenal.
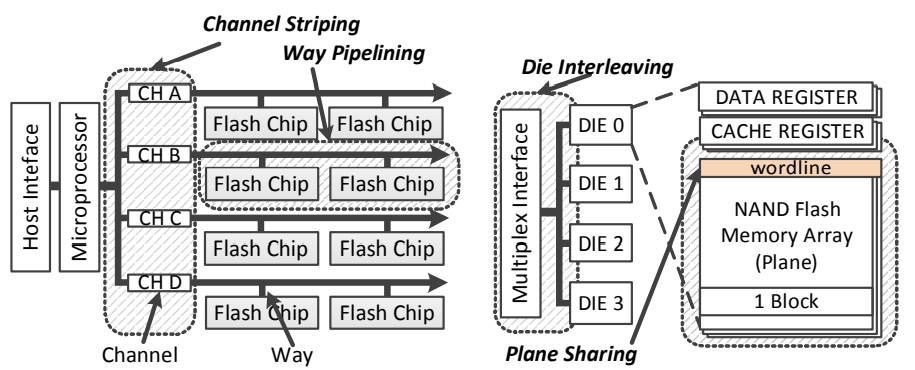
SSD is consisted of NAND chips connected to system-wide channels
- Each chip is consisted of multiple dies multiplexed by a common bus
- A chip (LUN) can process at most one request at a time
- activated by the command: chip enable (CE)
- advanced command can facilitate intra-chip parallelism: multi-plane mode, multi-die interleaving
- inter-chip parallelism: channel stripping and way pipelining
- When intra-chip parallelism is not utilized, performance will plateau as the number of dies in a chip increase, which happen to schedulers that operate merely on LUN-level 2 but cannot coalesce requests at die-level
| Level | Name | Behavior |
|---|---|---|
| Channel | channel striping | fully independent operations |
| Package (LUN) | way pipelining | serialized over shared channel, separate I/O requests can be pipelined |
| Die (chip) | die interleaving | implemented with interleave advanced command; like way pipelining, data and commands are serialized |
| Plane | plane sharing | implemented with multi-plane advanced command; perform same operation on multiple planes at same page offset (block can be different) |
Interleaving #
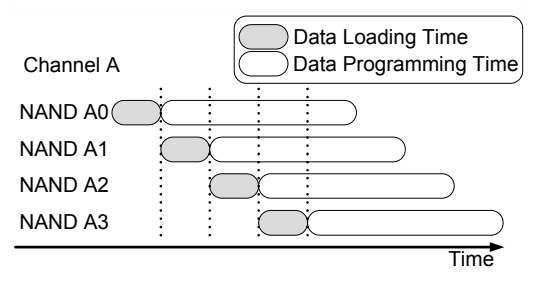
Because bus is shared, data transfer must be serialized, but the programming can be done independently.
Inter v.s Intra #
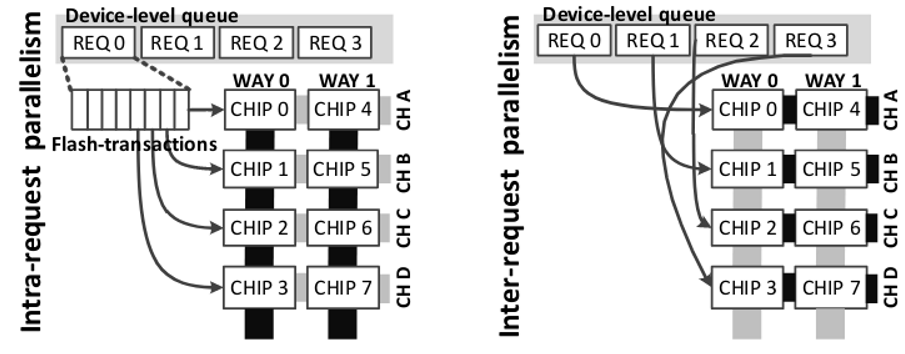
- Intra-request parallelism: split a LUN-level request into multiple chip, good for latency
- Inter-request parallelism: good for throughput
Data Placement #
- Writes are evenly distributed into multiple domains to balance free block and write latency, without regard to read parallelism
- At high queue depth, the congestion at one domain can become significant
- Higher resource utilization, but worse individual response time
- Random writes followed by sequential read has bad performance since the read sequence on the virtual address space has been jumbled. (sec 4.3 of 3)
Request Ordering & Mingling #
SSD buffers and reorders requests in Host Interface Logic.
- Parallelizing sequential read can result in mingled reads and disrupt detection of sequential pattern, but this happens only at low parallelism.
- Horizontal stripe has highest sequential write throughput, but degrades with more threads (see our discussion of OCSSD related works 4)
- In-memory DB writes two stream in separate circular queue in distant virtual addresses: transaction log & checkpointing. However, because the requests are mingled together and controller has zero knowledge, in GC many live data copies are still incurred. The root cause is different data live time. See (sec. 3.5 of SSD unwritten contract & multi-stream SSD)
- Question: DRAM requests and CPU requests are mostly bursted requests: a cache miss can incur other cache misses. For storage, it’s not definite that requests come in a burst. Could reordering requests introduce queuing delay?
Read & Write #
TODO
Queue Depth #
Queue Depth is the number of concurrent in-flight requests to the SSD. QD = 1 means issuing a second request only after the first one returns. In Unwritten Contract of Intel Optane SSD 5, the author compares throughput of different queue depths varying stride size (distance between consecutive 4K read):
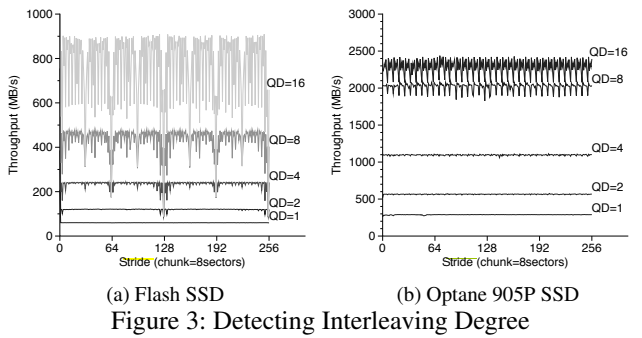
Throughput drops when concurrent request access the same parallelism unit. Optane has a flat layout of 7 memory dies while SSD contains multiple levels of parallelism (channel, chip and die), spread out during page allocation using policy like CFDP (see page allocation).
An Evaluation of Different Page Allocation Strategies on High-Speed SSDs, USENIX HotStorage 2012, Myoungsoo Jung et al. ↩︎ ↩︎
Sprinkler: Maximizing resource utilization in many-chip solid state disks, HPCA 2014, Myoungsoo Jung et al ↩︎
Revisiting Widely Held SSD Expectations and Rethinking System-Level Implications, SIGMETRICS 2013, Myoungsoo Jung et al ↩︎
Open-Channel SSD (What it is good for), CIDR 2020 ↩︎
Towards an Unwritten Contract of Intel Optane SSD, USENIX HotStorage 2019, Arpaci-Dusseau et al. ↩︎